À complexité égale, des réalités très différentes

Je termine l’article sur les types de complexités avec une situation où deux logiciels ont la même complexité, mais avec une répartition différente. L’un des logiciels a une complexité accidentelle beaucoup plus conséquente que l’autre.
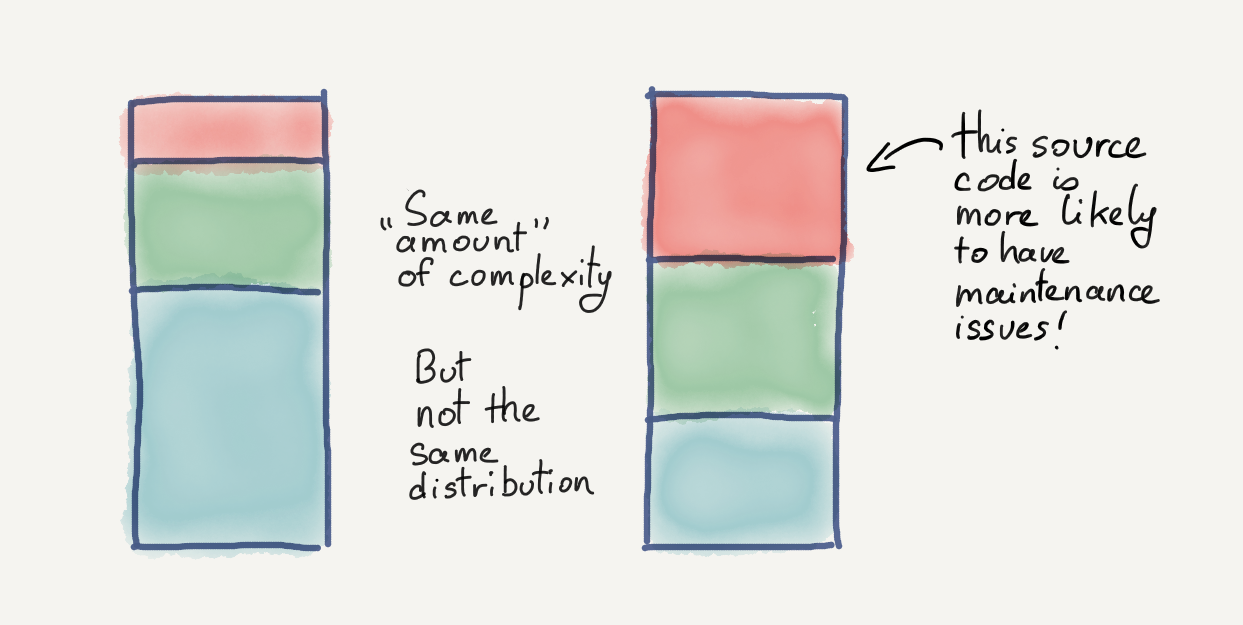
Dans cet article, nous allons voir pourquoi le code source associé à de la complexité accidentelle augmente les problèmes de qualité et de maintenance.
Pour commencer, il est important de noter que face à un code source complexe, la principale difficulté n’est pas de comprendre ce que fait le code, mais de comprendre pourquoi et comment il est apparu.
La complexité essentielle trouve son explication dans le métier
La complexité essentielle est liée à la complexité du problème métier. Aussi, il est simple de retrouver pourquoi ce code existe. Si votre code est aligné avec le problème auquel il répond, un utilisateur ou un expert métier est normalement capable d’expliquer l’existence de ce code.
La complexité obligatoire provient des contraintes techniques
Le code associé à de la complexité obligatoire trouve son origine dans une nécessité technique. Cette nécessité est souvent évidente. Dans le cas contraire, la documentation technique ou des collègues qui travaillent sur des problématiques similaires peuvent donner la réponse.
La complexité accidentelle, l’arbre qui cache la forêt
Déjà, ce type de complexité est un signe que le logiciel aurait pu être beaucoup plus simple. Et bien que ce soit frustrant, nous allons voir que ce n’est pas le principal problème.
En effet, c’est une situation où du code apparait malgré lui. Le résultat d’un choix malheureux, d’une décision prise « au cas où » ou d’un développement réalisé avec une vision à très court terme et qui n’a jamais été corrigé.
Ainsi, très rapidement, personne n’est réellement en mesure d’expliquer pourquoi le code source est conçu de cette façon. Même si l’explication paraissait évidente au moment de l’écriture. Ce code n’étant rattaché à aucune contrainte métier ou technique, il devient difficile de retrouver le contexte de sa création.
Nous avons tous déjà connu la situation où l’on se demande à quoi sert un morceau de code, pour se rendre compte que nous en sommes l’auteur. Notre mémoire est loin d’être fiable et être l’auteur d’un code source ne vous protège pas de cette perte de contexte. Alors imaginez pour un développeur qui n’est pas à l’origine du code.
Étant donné qu’il devient très difficile de comprendre l’histoire de ce code, il est très difficile de le retravailler (refactoring). La crainte de casser quelque chose par erreur est très forte. Ce code finit par devenir intouchable de peur de provoquer un bug en tentant de l’améliorer.
Ces morceaux de code source, laissés tels quels, s’accumulent avec le temps. Ils vont progressivement rendre illisible le reste du code source. Avec le risque de rendre impossible la modification de composants entiers de l’application.
C’est pourquoi, un logiciel avec une complexité accidentelle conséquente risque d’avoir des problématiques de qualités beaucoup plus rapidement.
Bien évidemment, ce n’est pas une règle absolue. Par exemple, certains projets connaissent des problèmes pour retrouver l’origine d’une complexité essentielle, car elle est liée à des règles métiers oubliés. Mais de manière générale j’ai pu observer que la complexité accidentelle était la plus difficile à retracer.
Dans les prochains articles, nous verrons comment garder la complexité sous contrôle. Pour être sûr de les recevoir, abonnez-vous à la newsletter !
Si vous l'avez apprécié, n'hésitez pas à partager cet article sur twitter, Linkedin, ou sur Slack.
Merci à @SebastienChemin & Olga Cojocariu qui m'ont apporté leur aide pour l’écriture de cet article